Requirements of a Web Crawler's Design
Requirements
Let’s highlight the functional and non-functional requirements of a web crawler.
Functional requirements
These are the functionalities a user must be able to perform:
- Crawling: The system should scour the WWW, spanning from a queue of seed URLs provided initially by the system administrator.
- Storing: The system should be able to extract and store the content of a URL in a blob store. This makes that URL and its content processable by the search engines for indexing and ranking purposes.
- Scheduling: Since crawling is a process that’s repeated, the system should have regular scheduling to update its blob stores’ records.
Question 1
Where do we get these seed URLs from?
There are two possible ways to create or gather seed URLs:
- We can manually create them
- We can scan the IP addresses for the presence of web servers
These seed URLs must be of good quality.
Question 2
Why are good quality seed URLs important and what happens if the seed quality is not good?
When we model WWW as a graph where URLs link one node to another, our goal is to discover as much of it as possible during the crawl.
Using a low-quality seed might limit the discovery to just a fraction of the WWW graph.
Question 3
How do we select seed URLs for crawling?
There are multiple approaches to selecting seed URLs. Some of them are:
- Location-based: We can have different seed URLs depending on the location of the crawler. Category-based: Depending on the type of content we need to crawl, we can have various sets of seed URLs.
- Popularity-based: This is the most popular approach. It combines both the aforementioned approaches. It groups the seed URLs based on hot topics in a specific area.
-------------------------
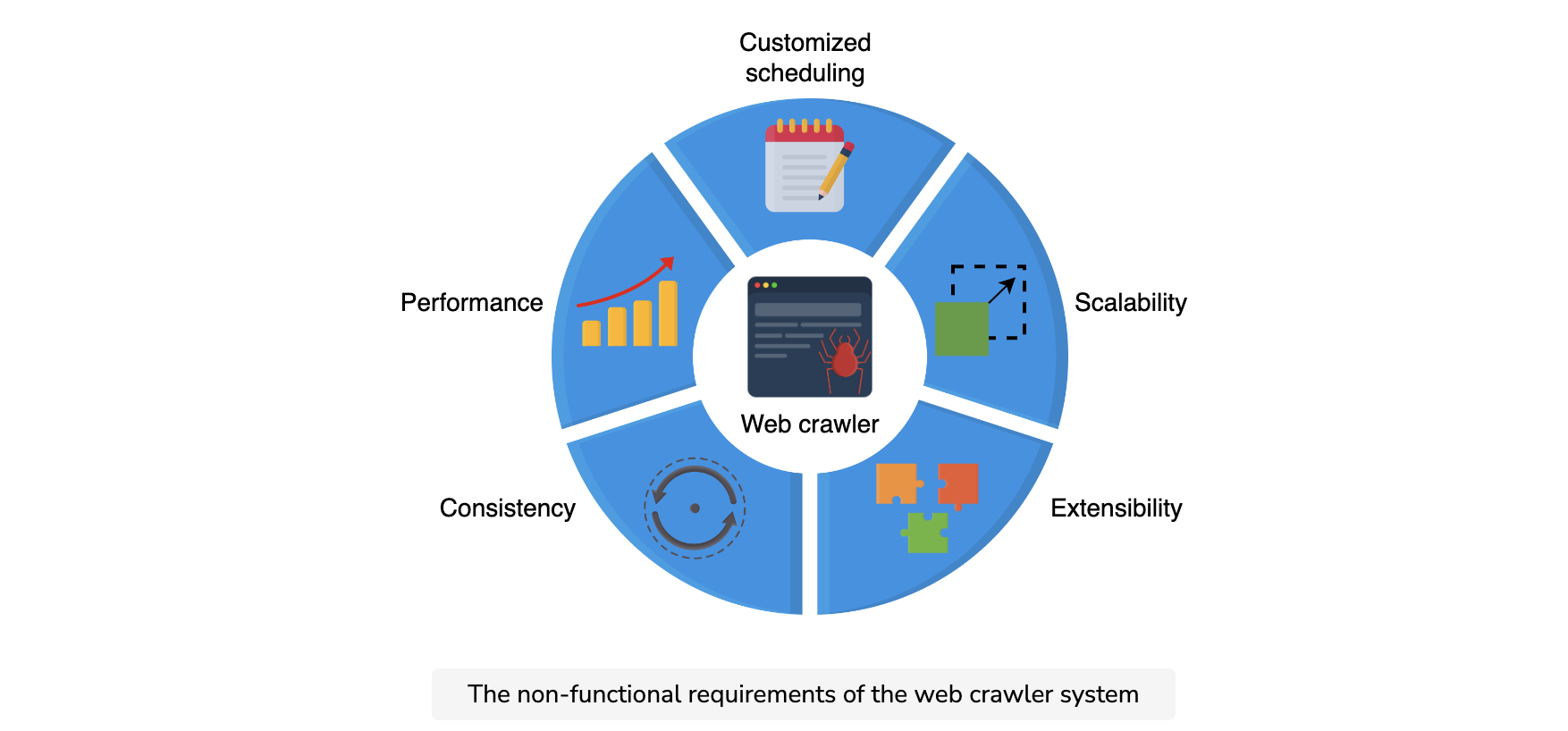
Non-functional requirements
- Scalability: The system should inherently be distributed and multithreaded, because it has to fetch hundreds of millions of web documents.
- Extensibility: Currently, our design supports HTTP(S) communication protocol and text files storage facilities. For augmented functionality, it should also be extensible for different network communication protocols, able to add multiple modules to process, and store various file formats.
Consistency: Since our system involves multiple crawling workers, having data consistency among all of them is necessary.
In the general context, data consistency means the reliability and accuracy of data across a system or dataset. In the web crawler’s context, it refers to the adherence of all the workers to a specific set of rules in their attempt to generate consistent crawled data.
- Performance: The system should be smart enough to limit its crawling to a domain, either by time spent or by the count of the visited URLs of that domain. This process is called self-throttling. The URLs crawled per second and the throughput of the content crawled should be optimal.
Tip\
Websites usually host a robot.txt file, which communicates domain-specified limitations to the crawler. The crawler should adhere to these limitations by all means.
---------------
- Improved user interface—customized scheduling: Besides the default recrawling, which is a functional requirement, the system should also support the functionality to perform non-routine customized crawling on the system administrator’s demands.
Resource estimation
We need to estimate various resource requirements for our design.
Assumptions
These are the assumptions we’ll use when estimating our resource requirements:
- There are a total of 5 billion web pages.
- The text content per webpage is 2070 KB.
- The metadata for one web page is 500 Bytes.
Storage estimation

It’ll take approximately 9.5 years to traverse the whole Internet while using one instance of crawling, but we want to achieve our goal in one day. We can accomplish this by designing our system to support multi-worker architecture and divide the tasks among multiple workers running on different servers.
Number of servers estimation for multi-worker architecture
Let’s calculate the number of servers required to finish crawling in one day. Assume that there is only one worker per server.
.png)
Case for multi-threaded server!
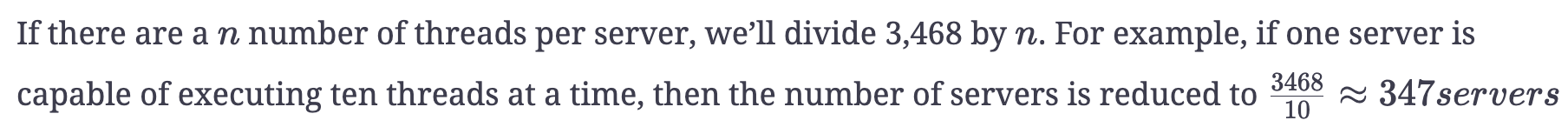
Bandwidth estimation
Since we want to process 10.35PB of data per day the total bandwidth required would be:

Let's play around with the initial assumptions and see how the estimates change in the following calculator:
Estimates Calculator for the Web Crawler
| Number of Webpages | 5 | Billion |
|---|---|---|
| Text Content per Webpage | 2070 | KB |
| Metadata per Webpage | 500 | Bytes |
| Total Storage | f10.35 | PB |
| Total Traversal Time on One Server | f9.5 | Years |
| Servers Required to Perform Traversal in One Day | f3468 | Servers |
| Bandwidth Estimate | f958.33 | Gb/sec |
Building blocks we will use
Here is the list of the main building blocks we’ll use in our design:
.png)
- Scheduler is used to schedule crawling events on the URLs that are stored in its database.
- DNS is needed to get the IP address resolution of the web pages.
- Cache is utilized in storing fetched documents for quick access by all the processing modules.
- Blob store’s main application is to store the crawled content.
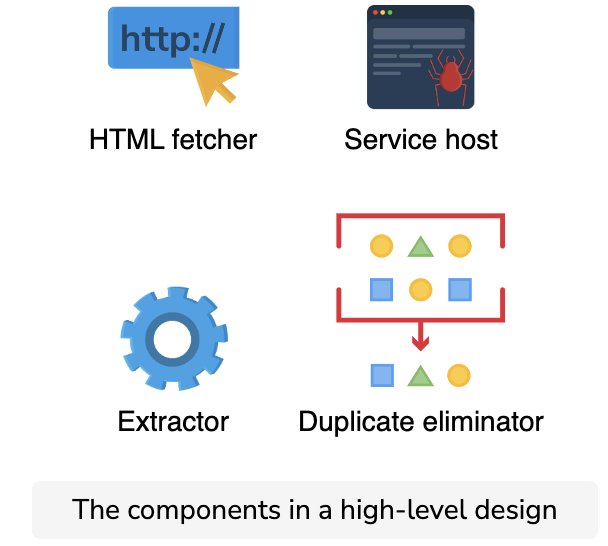
Besides these basic building blocks, our design includes some additional components as well:
- The HTML fetcher establishes a network communication connection between the crawler and the web hosts.
- The service host manages the crawling operation among the workers.
- The extractor extracts the embedded URLs and the document from the web page.
- The duplicate eliminator performs dedup testing on the incoming URLs and the documents.
In the next lesson, we’ll focus on the high-level and detailed design of a web crawler.