Eventual Consistency
What is eventual consistency?
Eventual consistency is a data consistency model that enables the datastores to be highly available. It is also known as optimistic replication and is key to distributed systems.
So, how does it work exactly?
Let’s understand this with the help of a use case.
Real-world use case
Think of a popular microblogging site deployed worldwide in different geographical regions like Asia, America, Europe, etc. Each geographical region has multiple data center zones: North, East, West, and South. And each of these data center zones has multiple clusters with numerous server nodes running.
These server nodes are application server nodes, message queue nodes, database nodes and nodes powering other components of an application.
In this lesson, we will focus on the database nodes that run in different data center zones across continents, enabling the micro-blogging site to persist data efficiently.
Since there are so many nodes running, there is no single point of failure. The datastore service is highly available. Even if a few nodes go down, the persistence service as a whole is still up.
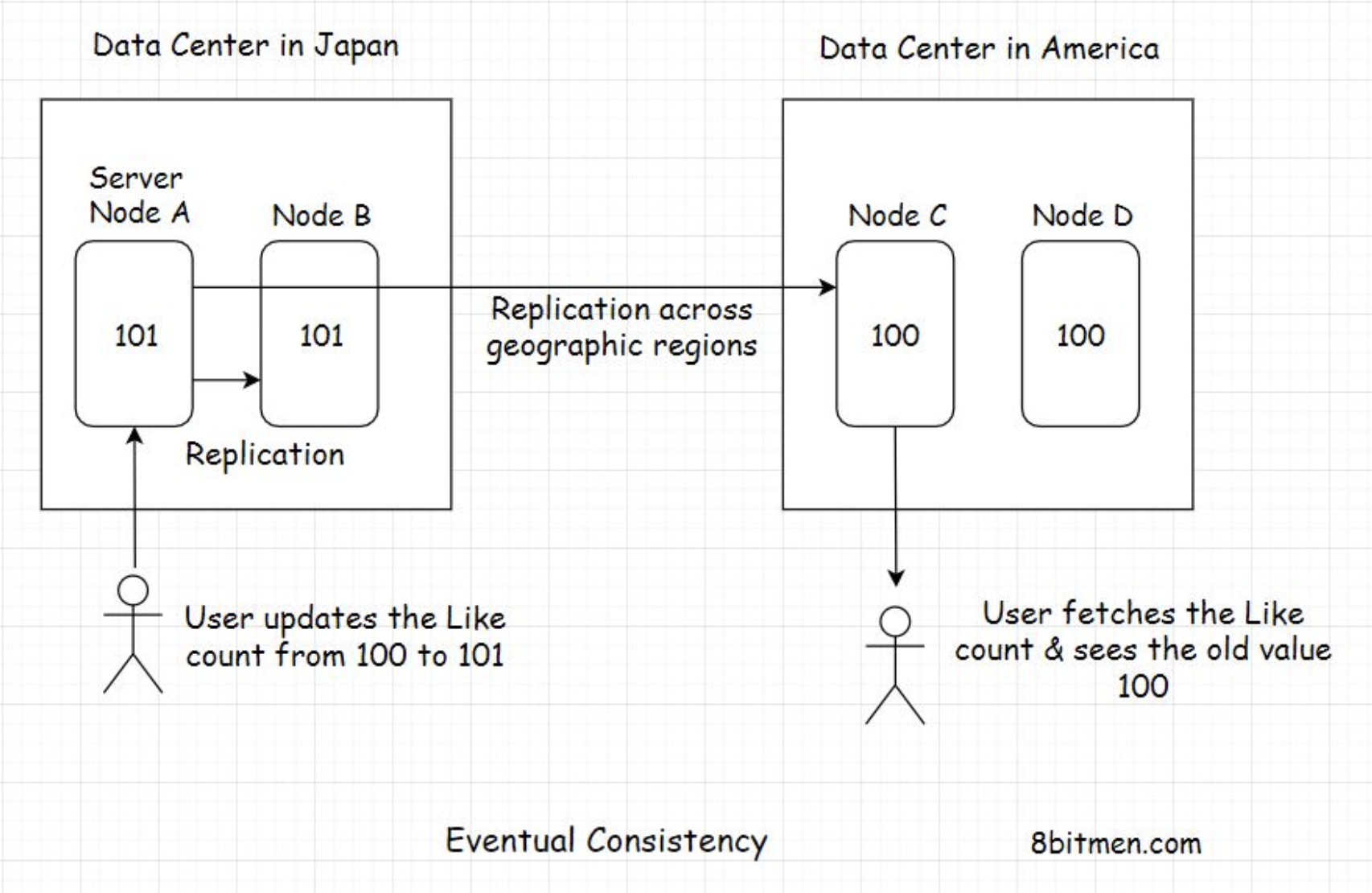
Now assume a celebrity creates a tweet on the website that goes viral, and everybody around the world starts liking it.
At a point in time, a user in Japan likes the tweet, which increases the like count of the tweet from, say, 100 to 101. At the same time, a user in America, a different geographical zone, clicks on the tweet and sees the like count as 100, not 101.
Why did this happen?
Because the new updated value of the tweet’s like counter would need some time to move from Japan to America and update the server nodes running there, reaching a consistent state globally.
Because of the geographical distance between the two continents, the user in America sees an old inconsistent value, that is, 100.
However, when they refresh their web page after a few seconds, the like counter value gets updated to 101. The data was initially inconsistent but eventually became consistent across all the server nodes deployed around the world. This is what eventual consistency is. Eventually, the data became consistent.
Let’s take it one step further. What if, at the same time, both the users in Japan and America like the tweet and a user in another geographic zone, say Europe, sees the tweet?
In this scenario, all the nodes in different geographic zones will have different tweet like counts, and they will take some time to reach a consensus.
The upside of eventual consistency is that the system can add new nodes on the fly. Also, the database nodes are available to the application enabling the end-users to perform write operations continually without the need to lock any of the database nodes.
With the eventual consistency data model, millions of users worldwide can update the tweet’s like counter concurrently without having to wait for the system to reach a consistent state across all nodes deployed globally. This feature enables the system to be highly available.
Eventual consistency fits best for use cases where the data accuracy doesn’t matter much, like in the use case above.
Other eventual consistency use cases are: the system keeping the count of concurrent users watching a live video stream, dealing with massive amounts of analytics data, a slight data inaccuracy in real-time won’t matter much.
On the contrary, there are use cases where the data has to be laser accurate, like in banking and stock markets. We just cannot have our systems eventually consistent. In these use cases, we need strong consistency.
Let’s discuss it in the next lesson.