Design Considerations of Yelp
Introduction
We discussed the design, building blocks, components, and the entire workflow of our system in the previous lesson, which brought up a number of interesting questions that now need answering. For example, what approach do we use to find the places, or how do we rank places based on their popularity? This lesson addresses important design concerns like the ones we just mentioned. The table given below summarizes the goals of this lesson.
Summary of the Lesson
| Section/Sub-section | Purpose |
|---|---|
| Searching | This process divides the world into segments to optimize the search, so that all nearby sites in a given location and radius can be identified. |
| Storing Indexes | We index the places to improve query performance and estimate the storage required for all of the indexes. |
| Searching Using Segments | We search all the desired places by combining the segments. |
| Dynamic Segments | We solve the static segment limitations using dynamic segments. |
| Searching Using a QuadTree | We explore the searching functionality using a QuadTree. |
| Space Estimations for a QuadTree | We estimate the storage required for a QuadTree. |
| Data Partitioning | We look into the options we can use to partition data. |
| Ensuring Availability | We look into how we’ll ensure the availability of the system. |
| Inserting a New Place | We look into how we’ll insert the place in a QuadTree. |
| Ranking Popular Places | We rank the places of the system. |
| Evaluation | We evaluate how our system fulfills the non-functional requirements. |
Searching
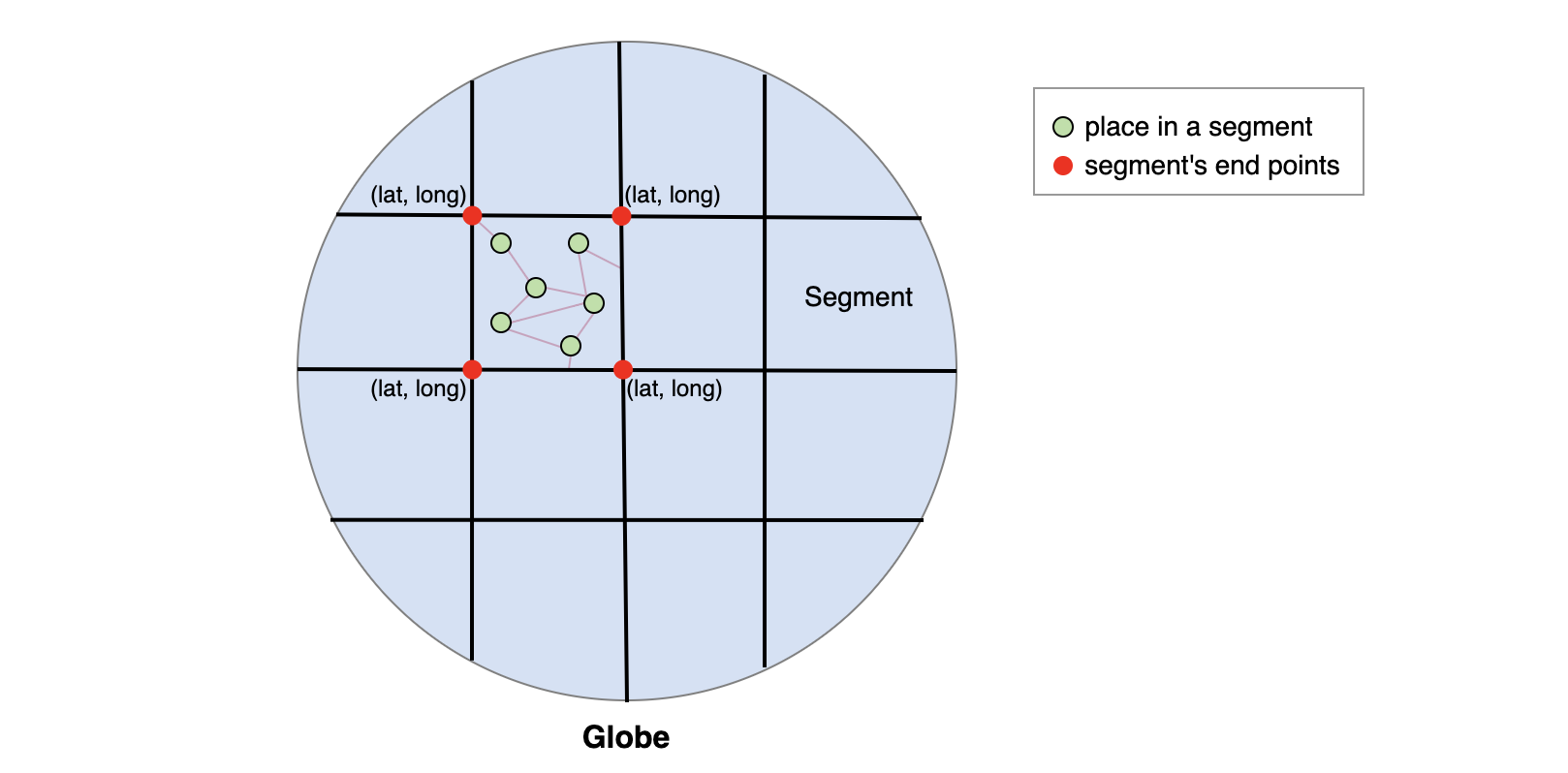
From Google Maps, we were able to connect segments and meet the scalability challenge to process a large graph efficiently. The graph of the world had numerous nodes and vertices, and traversing them was time-consuming. Therefore, we divided the whole world into smaller segments/subgraphs to process and query them simultaneously. The segmentation helps us improve the scalability of the system.
Each segment will be of the size 5×5 miles and will contain a list of places that exist within it. We only search a few segments to locate destinations that are close by. We can use a given location and defined radius to find all the nearby segments and identify sites that are close.
Points to Ponder
Question 1
How will we find nearby places if we create a table for storing all places?
We can make a table of places that have Place_ID as a unique ID and store each place in it. The longitude and latitude columns help us specify the exact location. Indexing both of these columns can help us fetch data efficiently. We can specify each location as a pair of latitude (M) and longitude (N). We can also search for a place within a given radius of R by finding all the places between the latitude M-R and M+R and the longitude N-R and N+R. We can apply Dijkstra’s algorithm to find the distance between two points.
Question 2
How efficient will our searching be when based on the table?
We can have multiple lists of places within (M-R, M+R) and (N-R, N+R). It’ll be a challenge to handle concurrent requests. When queries that are used to fetch the places will be coming at a high rate for different segments, the response time and performance will be affected.
------------------
We can store all the places in a table and uniquely identify a segment by having a segment_ID. We can index each segment in the database. Now, we have limited the number of segments we need to search, so the query will be optimized and return results quickly.
Improve data fetching
We use a key-value store for quick access to places in the segments. The key is the segment_ID, while the value contains the list of places in that segment. Let’s estimate how much space we need to store the indexes.
We can usually store a few MBs in the value of the key-value store. If we assume that each segment has 500 places then it will take up 500×1296 �����=0.648��500×1296 Bytes=0.648MB, and we can easily store it as a value.
The total area of the earth is around 200 million square miles, and the land surface area is about 60 million square miles. If we consider our radius to be ten miles, then we’ll have 6 million segments. An 8-Byte identifier will identify each segment.
Let’s calculate how much memory we need.
| Total Area of the Earth (Million Square Miles) | 60 |
|---|---|
| Search Radius (Miles) | 10 |
| Number of Segments (Millions) | f6 |
| Segment_ID (Bytes) | 8 |
| Place_ID (Bytes) | 8 |
| Number of Places (Millions) | 500 |
| Total Space (TB) | f4.048 |
Search using segments
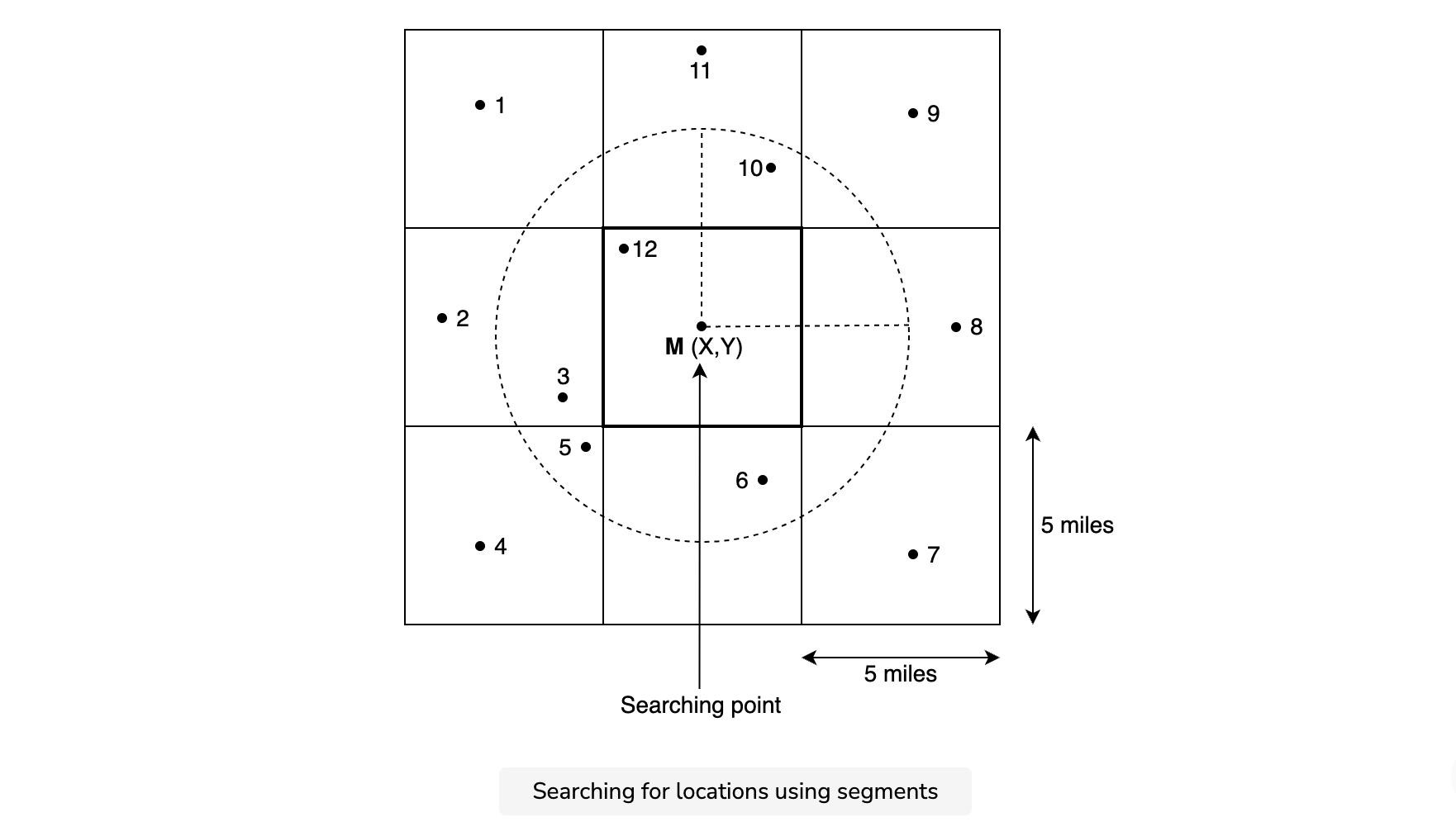
A user may select a radius for searching places that aren’t present in a single segment. So, we need to combine multiple segments by connecting the segments to find locations within the specified radius—say, five miles.
First, we constrain the number of segments. This reduces the graph size and makes the searching process optimizable. Then, we identify all the relevant locations, compute the distance from the searching point, and show it to the user.
Question
Can you identify a problem with the current approach?
Our locations are not evenly distributed across segments, and this approach may still take a long time to run on segments with a lot of places. For example, in a city like New York, we can have lots of places even within a small radius because it is a densely-populated area. And for less populated areas, the same radius might not have enough places, and we might need to expand our radius to find more.
---------------
Dynamic segments
We solve the problem of uneven distribution of places in a segment by dynamically sizing the segments. We do this by focusing on the number of places. We split a segment into four more segments if the number of places reaches a certain limit. We assume 500 places as our limit. While using this approach, we need to decide on the following questions:
- How will we map the segments?
- How will we connect to other segments?
We use a QuadTree(A QuadTree is a tree data structure in which each internal node has exactly four children. QuadTrees are the two-dimensional analog of octrees and are most often used to partition a two-dimensional space by recursively subdividing it into four quadrants or regions. The data associated with a leaf cell varies by application, but the leaf cell represents a “unit of interesting spatial information”. Source: Wikipedia) to manage our segments. Each node contains the information of a segment. If the number of places exceeds 500, then we split that segment into four more child nodes and divide the places between them. In this way, the leaf nodes will be those segments that can’t be broken down any further. Each leaf node will have a list of places in it too.
Search using a QuadTree
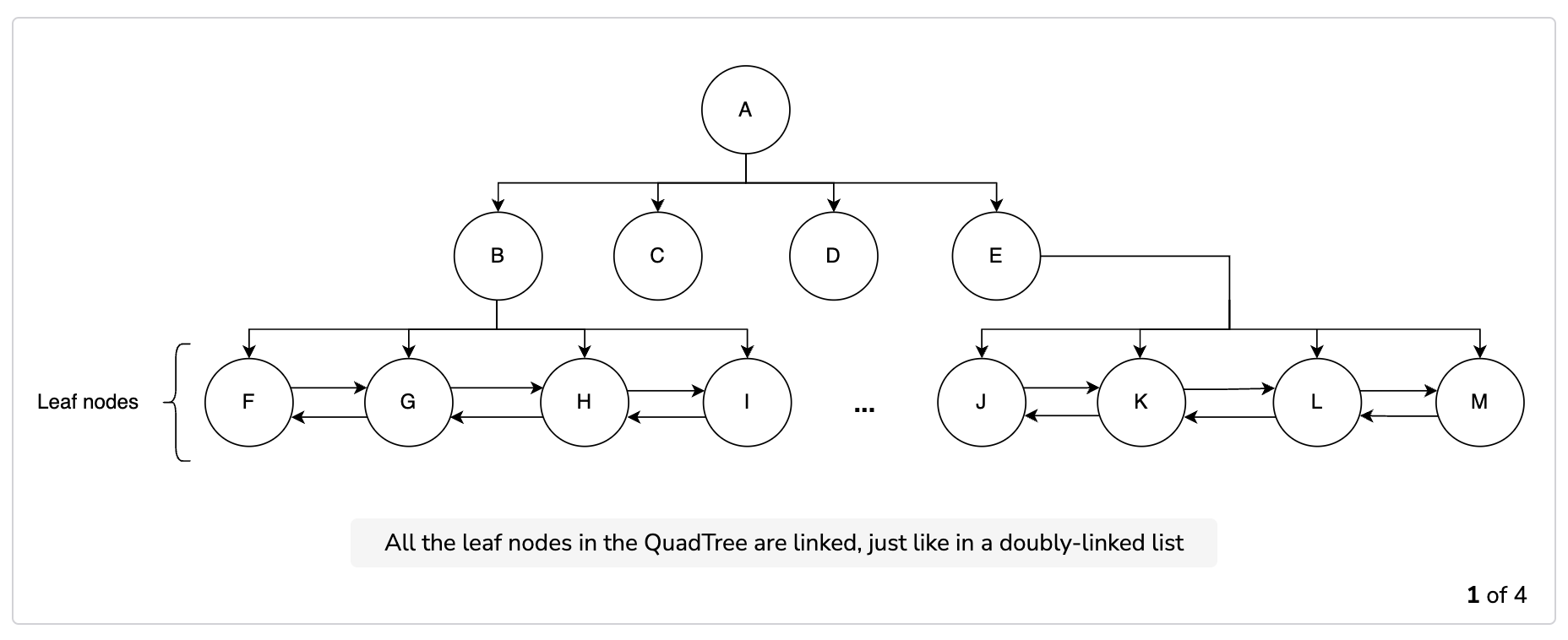
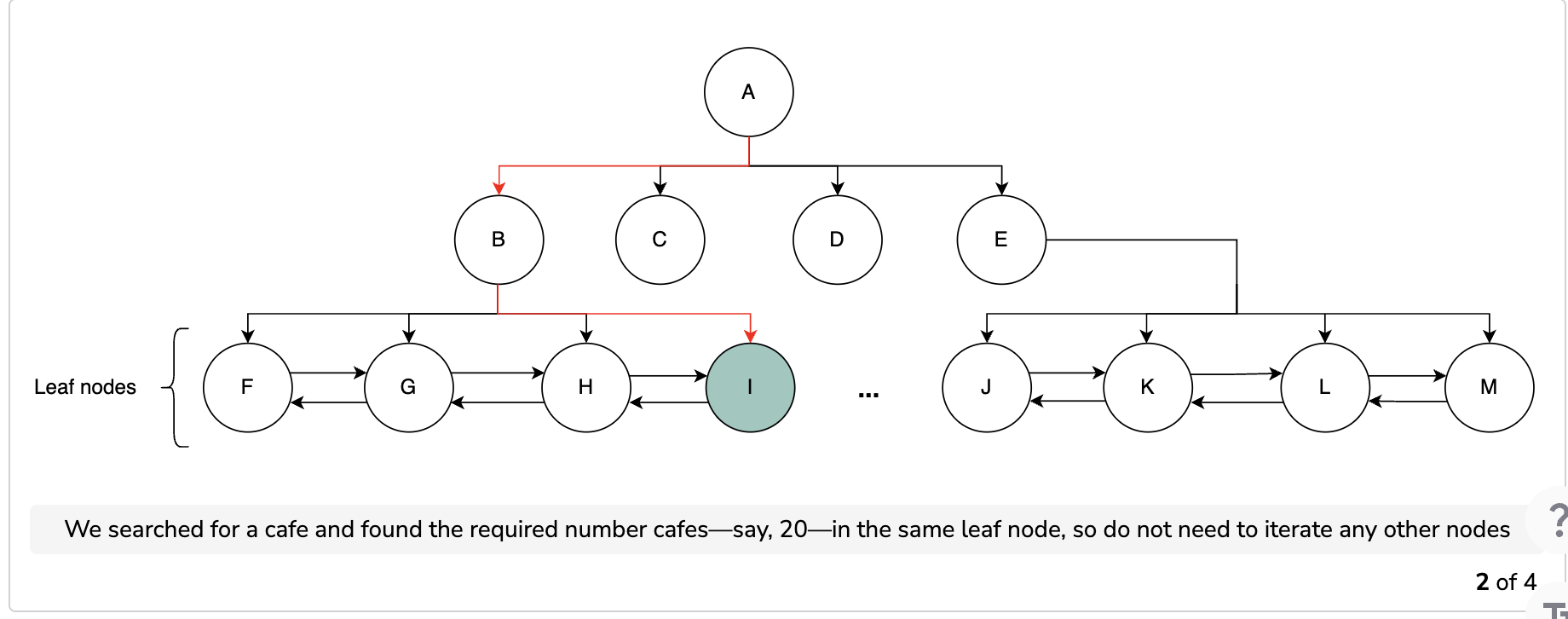
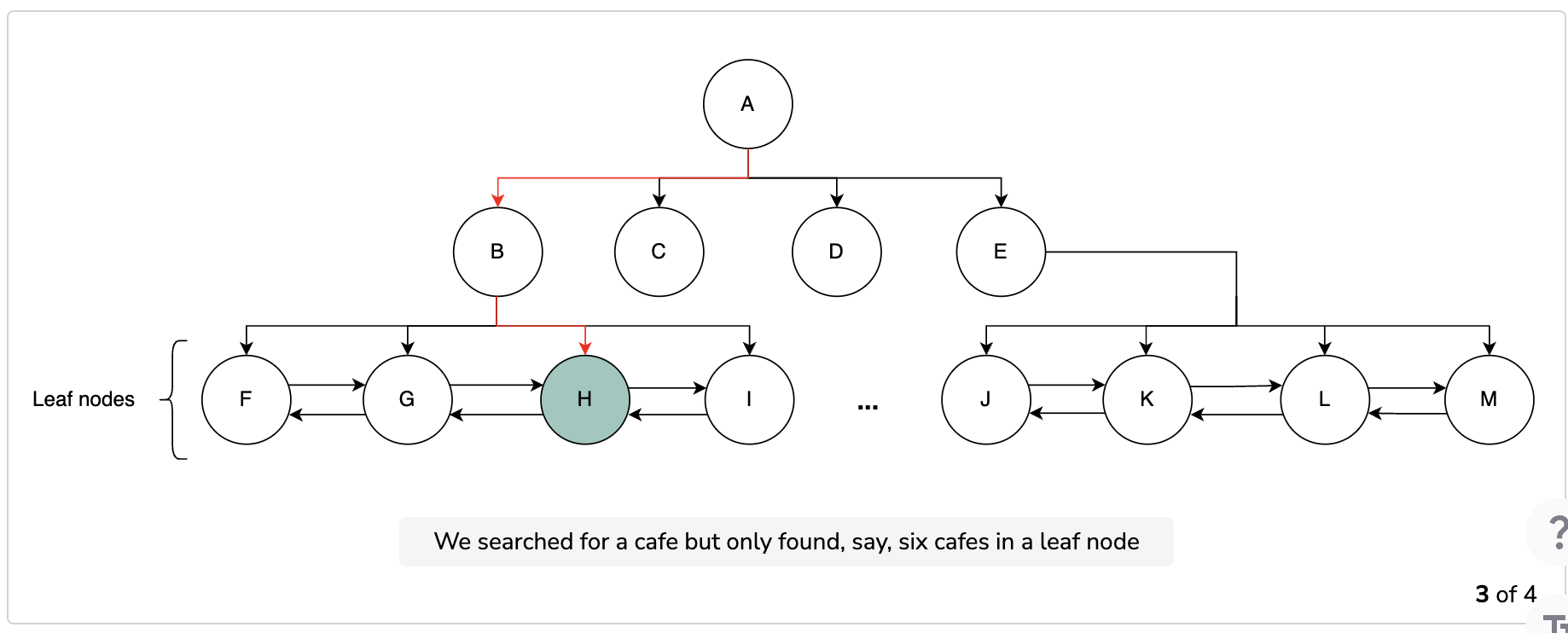
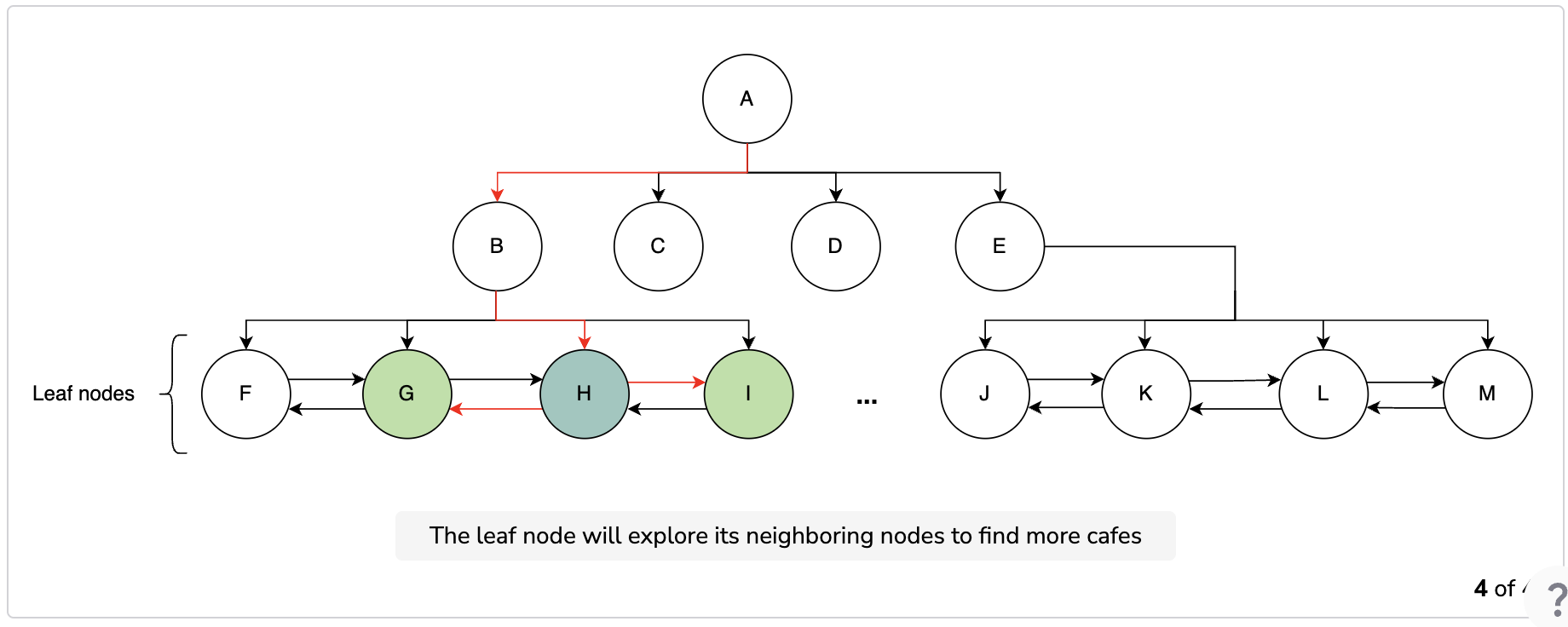
We start searching from the root node and continue to visit the nodes to find our desired segment. We check every node to see if it has more child nodes. If a node has no more children, then we stop our search because that node is the required one. We also connect each child node with its neighboring nodes with a doubly-linked list. All the child nodes of all the parents nodes are connected through the doubly-linked list. This list allows us to find the neighboring segments when we can move forward and backward as per our requirement. After identifying the segments, we have the required PlaceID values of the places and we can search our database to find more details on them.
Question
Is there an alternative approach to find the neighboring segments?
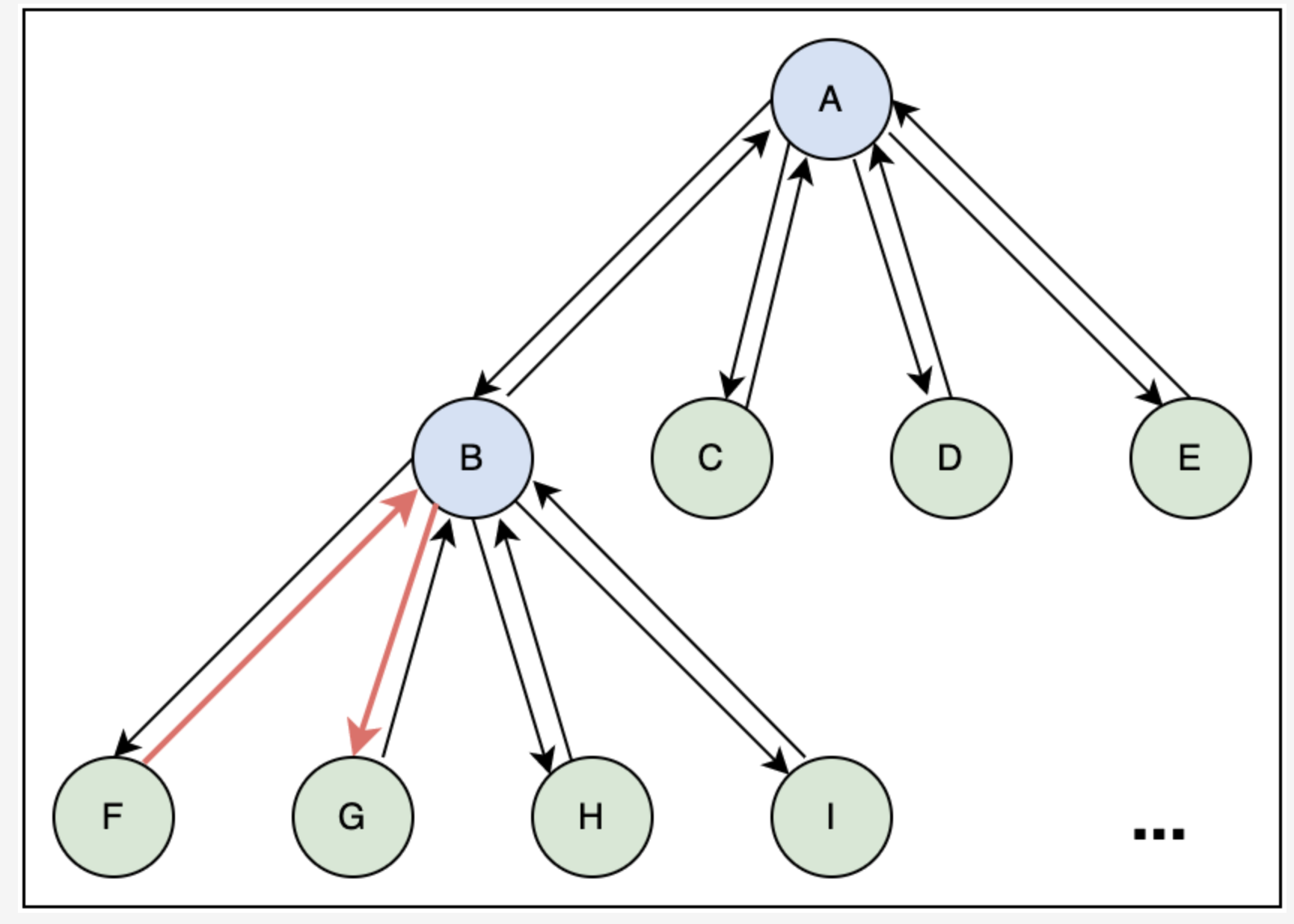
We can use the pointers of parent nodes to find the neighboring segments. In each node, we can keep a pointer that points towards the parent node. Every parent node has pointers to its children nodes, so we can use those to find the adjacent leaf nodes. We can extend our search by going up through the parent pointers.
In the following illustration, node F can find its neighboring node, G, by first going to the parent node, B, and then to G.
----------------
The following slides show how the process of searching for a place works. If a node has the places we need, we stop there. Otherwise, we explore more nodes until we reach our search radius. After finding the node, we query the database for information related to the places and return the desired ones.
Storage space estimation for QuadTrees
Let’s calculate the storage we need for keeping QuadTrees:

We can easily store a QuadTree on a server.
Let’s try the following calculator to calculate the storage needed for a QuadTree:
| PlaceID, Latitude, and Longitude (Bytes) | 24 |
|---|---|
| Total Number of Places (Millions) | 500 |
| Total Space Needed to Store All Places (GB) | f12 |
| Limit of Places for Each Segment | 500 |
| Number of Segments (Millions) | f1 |
| Number of Pointers to Hold Children Pointers | 4 |
| Size of Each Pointer (Bytes) | 8 |
| Total Space to Store All Internal Nodes (MB) | f10.67 |
| Total Space to Store QuadTrees (GB) | f12.01 |
Data partitioning
Keeping 20% growth per year in mind, the number of places will increase. We can partition data on the following basis:
Regions: We can split our places into regions on the basis of zip codes. This way, all the places that belong to a specific region are stored on a single node. We store information on the region along with the place, so that we can query on the basis of regions too. We can use the user’s region to find the places in that specific region.
This data partitioning comes with a few challenges. For example, if a region becomes popular during tourist season, it can affect the performance of our system. We might have numerous queries on the server that might result in slow responsiveness to user queries.
PlaceID: We can partition data on the basis ofPlaceIDinstead of the region to avoid the query overload in popular seasons or rush hours. We can use a key-value store to store the places. In this case, the key is thePlaceIDand the value contains the server in which that place is stored. This will make the process of fetching places more efficient.
So, we’ll opt for partitioning on the basis of places. Moreover, we’ll also use caches for popular places. The cache will have information about that particular place.
Ensure availability
Consider a scenario where multiple people in the same radius place a search request. If we have a single QuadTree, it’ll affect the availability of the users. So, we can’t rely on a single QuadTree. To cater to this problem, we replicate our QuadTrees on multiple servers to ensure availability. This allows us to distribute the read traffic and decrease the response time. QuadTrees are built on a server, so we can use the server ID as a key to identify the server on which the QuadTree is present. The value is the list of places that the QuadTree holds. The key-value store eases the rebuilding of the QuadTree in case we lose it.
Question
How will the leader-follower approach help us in replication?
We’ll have a single leader and two followers. The leader will have the QuadTree and it’ll handle all the write requests. It’ll update the followers about any change made to the QuadTrees synchronously, so there’ll be a chance of delay. The followers will handle all the read requests. In case a follower dies, we’ll choose another follower and replicate the data to it. If the leader is down, we‘ll choose any of the followers to step in as the leader. This way, we’ll be able to replicate our QuadTrees onto three servers.
--------------
Insert a new place
We insert a new place into the database as well as in our QuadTree. We find the segment of the new place if the QuadTree is distributed on different servers, and then we add it to that segment. We split the segment if required and update the QuadTree accordingly.
Rank popular places
We need a service, a rating calculator, which calculates the overall rating of a service. We can store the rating of a place in the database and also in the QuadTree, along with the ID, latitude, and longitude of the place. The QuadTree returns the top 50 or 100 popular places within the given radius. The aggregator service determines the actual top places and returns them to the user.
Note: We don’t expect the rating to be updated within hours, as such frequent changes in QuadTrees or databases can be expensive. We update them once a day, when the load is minimal.
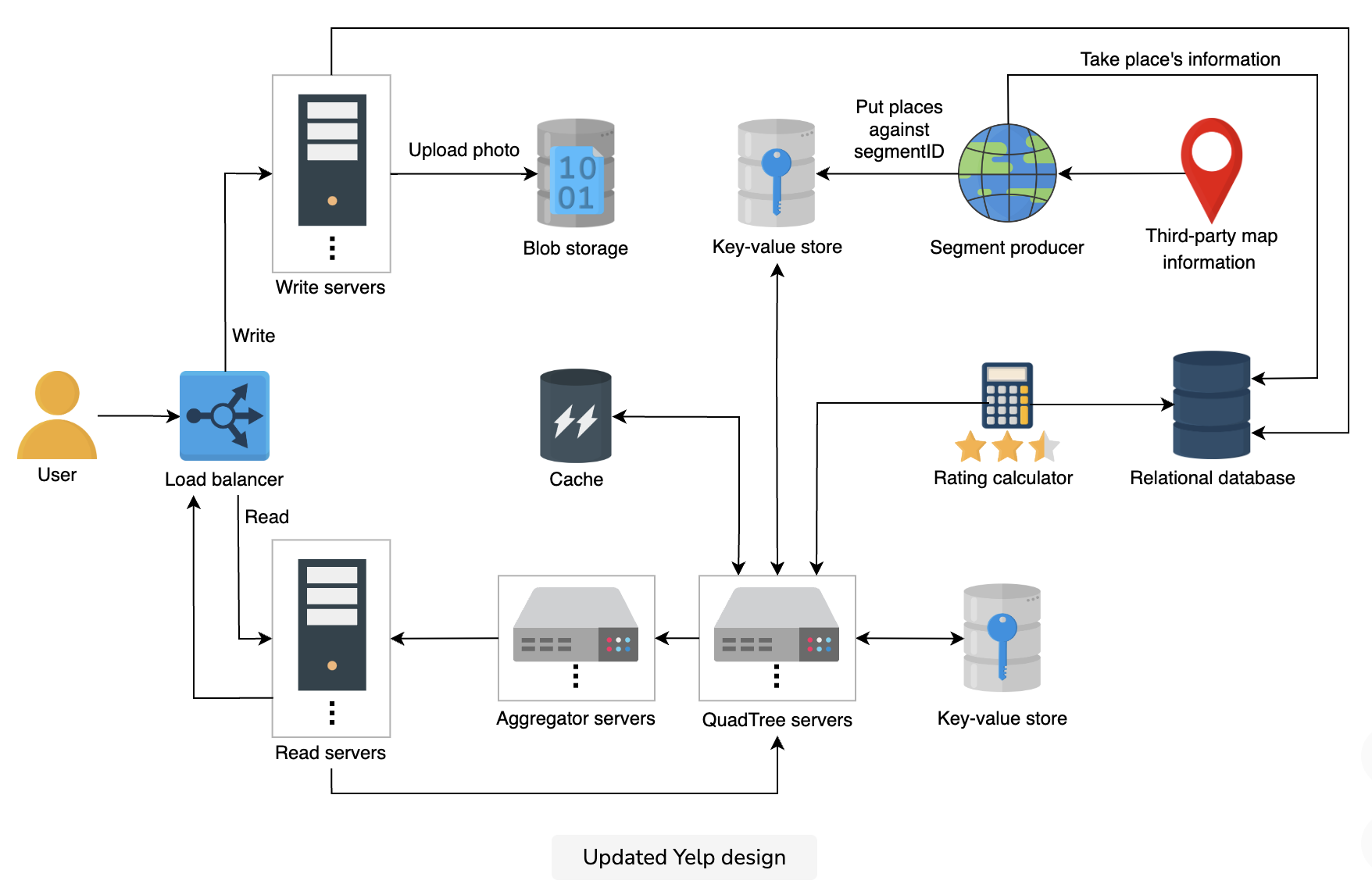
Finalized design
We added a few new components to our design. We introduced caches to store popular places. This allows us to fetch the places much faster. Moreover, we also added a rating calculator that sorts the places based on their ratings. This will enhance user experience, since the places with a good rating will be displayed first.
The updated design of our system is shown below:
Evaluation
Let’s see how our system design fulfills our requirements.
- Availability: We partitioned the data into smaller segments instead of having to deal with a huge dataset consisting of all the places on the world map. This made our system highly available. We also replicated the QuadTrees data using key-value stores to ensure availability.
- Scalability: We split the whole world into smaller dynamic segments. This allows us to search for a place within a specific radius and shorten our search area. We then used QuadTrees in which each child node holds a single segment. Upon adding or removing a place, we can restructure our QuadTrees. So, we were able to make our system scalable.
- Performance: We reduced the latency by using caches. We cached all the famous and popular places, so request time was minimized.
- Consistency: The users have a consistent view of the data regarding places, reviews, and photos because we used reliable and fault-tolerant databases like key-value stores and relational databases.
Summary
The proximity-based servers allow the user to search for a specific place or places nearby. The map data of the world is huge and dividing it into segments and finding the specific segment was a challenge in itself. So, we used QuadTrees to optimize our search and provided the user with a list of places with minimum latency.