Polyglot Persistence
What Is polyglot persistence?
Polyglot persistence means using several distinct persistence technologies such as MySQL, MongoDB, Memcache, Cassandra, etc., together in an application to fulfill its different persistence requirements.
Let’s understand this with the help of an example.
Real-world use case
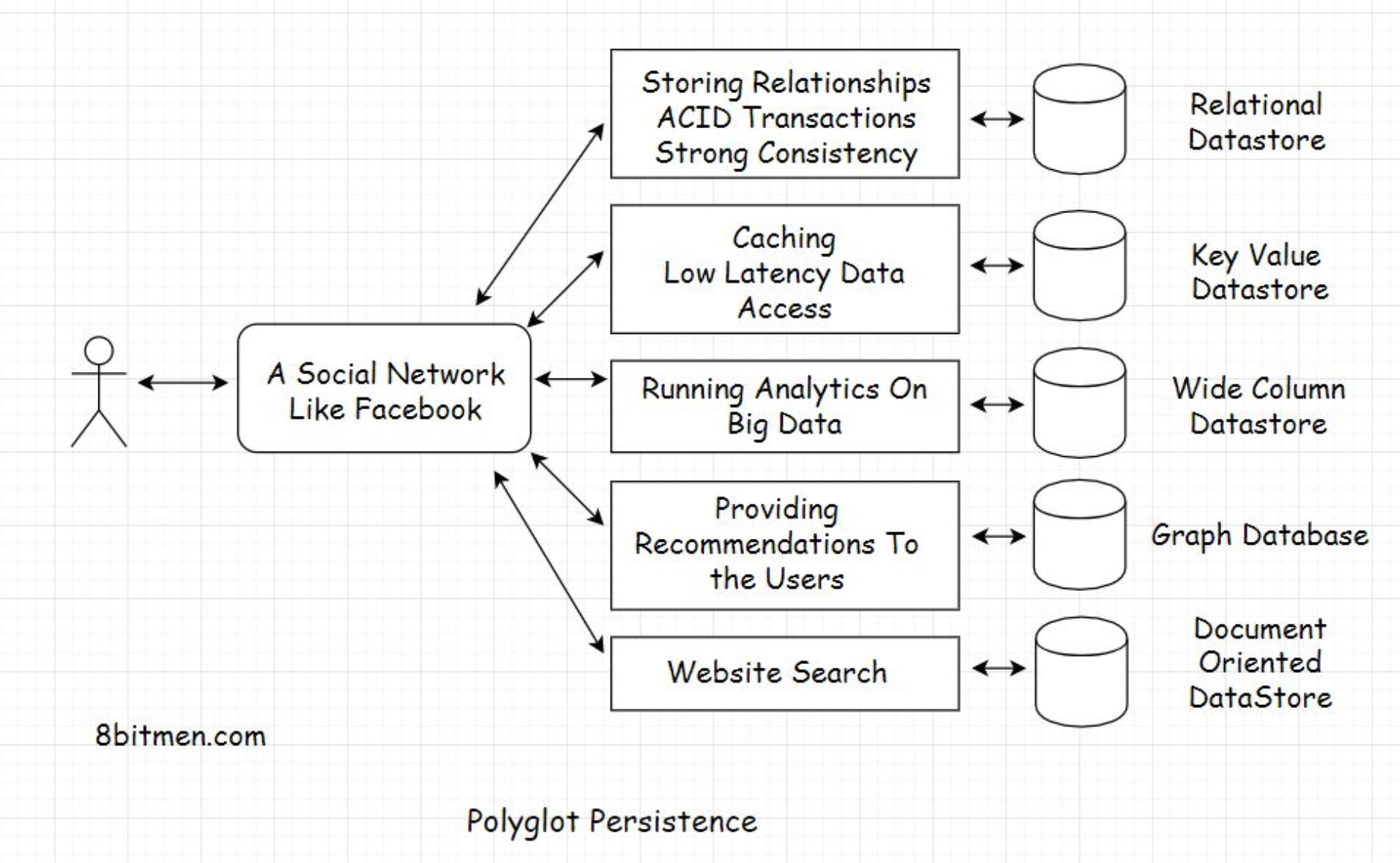
Imagine designing a social networking app like Facebook.
Relational database
To store relationships like persisting friends of a user, friends of friends, what rock band a user likes, what food preferences users have in common with their friends, etc., we can pick a relational database like MySQL or a graph database like Neo4J.
Key-value store
For low latency access of the frequently accessed data, we would need to implement a cache using a key-value store like Redis or Memcached.
We can use the same key-value data store to store user sessions in a distributed system achieving a consistent state across the clusters.
Wide column database
To understand user behavior, we need to set up an analytics system to analyze the big data generated by the users. We can do this using a wide-column database like Cassandra or HBase.
ACID transactions and strong consistency
The popularity graph of our application continues to rise and doesn’t appear to slow down. The businesses now want to run ads on our portal. Hallelujah! :)
To enable the businesses pay for the ads they intend to run on our platform, we need to implement a payment system. For this, we need ACID transactions and strong consistency—time to pick a relational database.
Graph database
To keep the users stay longer on our application and enhance their browsing experience, we have to start recommending the latest content to the users to keep them engaged. We need to implement a recommendation system. For this, a graph database would fit best.
By now, our application is loaded with multiple features, and everyone loves it. How cool would it be if a user could run a search for other users on the platform, business pages, groups, and more and connect with them?
Document Oriented Store
To implement this, we can use an open-source document-oriented datastore like Elasticsearch. The product is pretty popular in the industry for implementing a scalable search feature on apps. All the search-related data can be streamed to the elastic store from other databases powering different features of our app.
Complexity that comes along
We got an insight into how we leverage multiple databases to fulfill the different persistence requirements of our application. However, one significant downside of this approach is the increased complexity in making all these different technologies work together in a distributed environment.
A lot of effort goes into building, managing and monitoring polyglot persistence systems. What if there was something simpler? Something that would save us the pain of putting together everything ourselves.
Well, there is.
What?
We will find out in the lesson up-next.