Design of a Web Crawler
Design
This lesson describes the building blocks and the additional components involved in the design and workflow of the web crawling process with respect to its requirements.
Components
Here are the details of the building blocks and the components needed for our design:
- Scheduler: This is one of the key building blocks that schedules URLs for crawling. It’s composed of two units: a priority queue and a relational database.
- A priority queue (URL frontier): The queue hosts URLs that are made ready for crawling based on the two properties associated with each entry: priority and updates frequency.
- Relational database: It stores all the URLs along with the two associated parameters mentioned above. The database gets populated by new requests from the following two input streams:
- The user’s added URLs, which include seed and runtime added URLs.
- The crawler’s extracted URLs.
Question 1
Can we estimate the size of the priority queue? What are the pros and cons of a centralized and distributed priority queue.
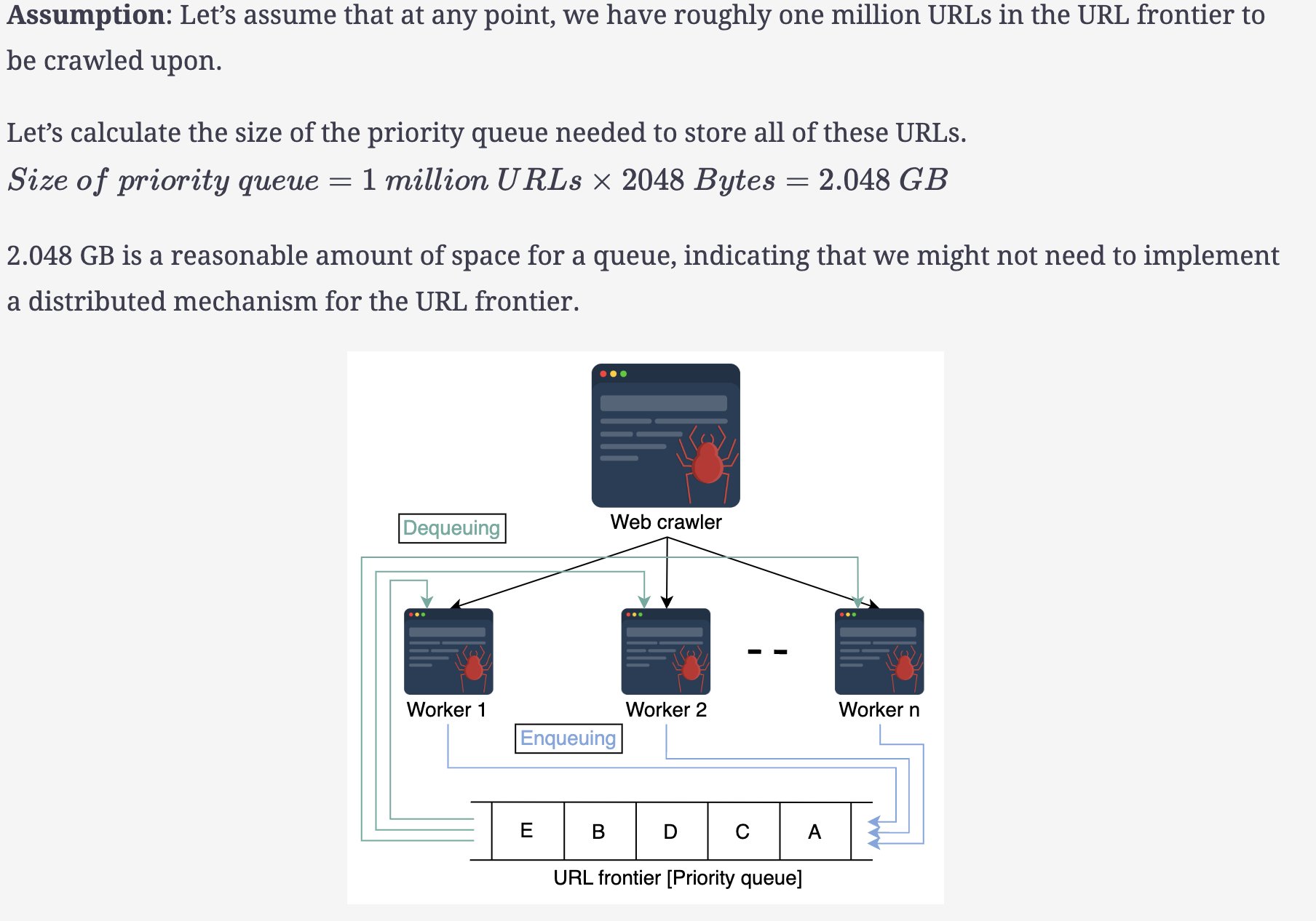
Having a single queue is beneficial for the deduplication of redundant links and better for the overall crawler resources. We’ll handle the recrawling priority and frequency another way, as explained in the next sections, for which we need the distribution mechanism.
Question 2
How will we distribute the URL frontier among different workers and what purpose will this serve?
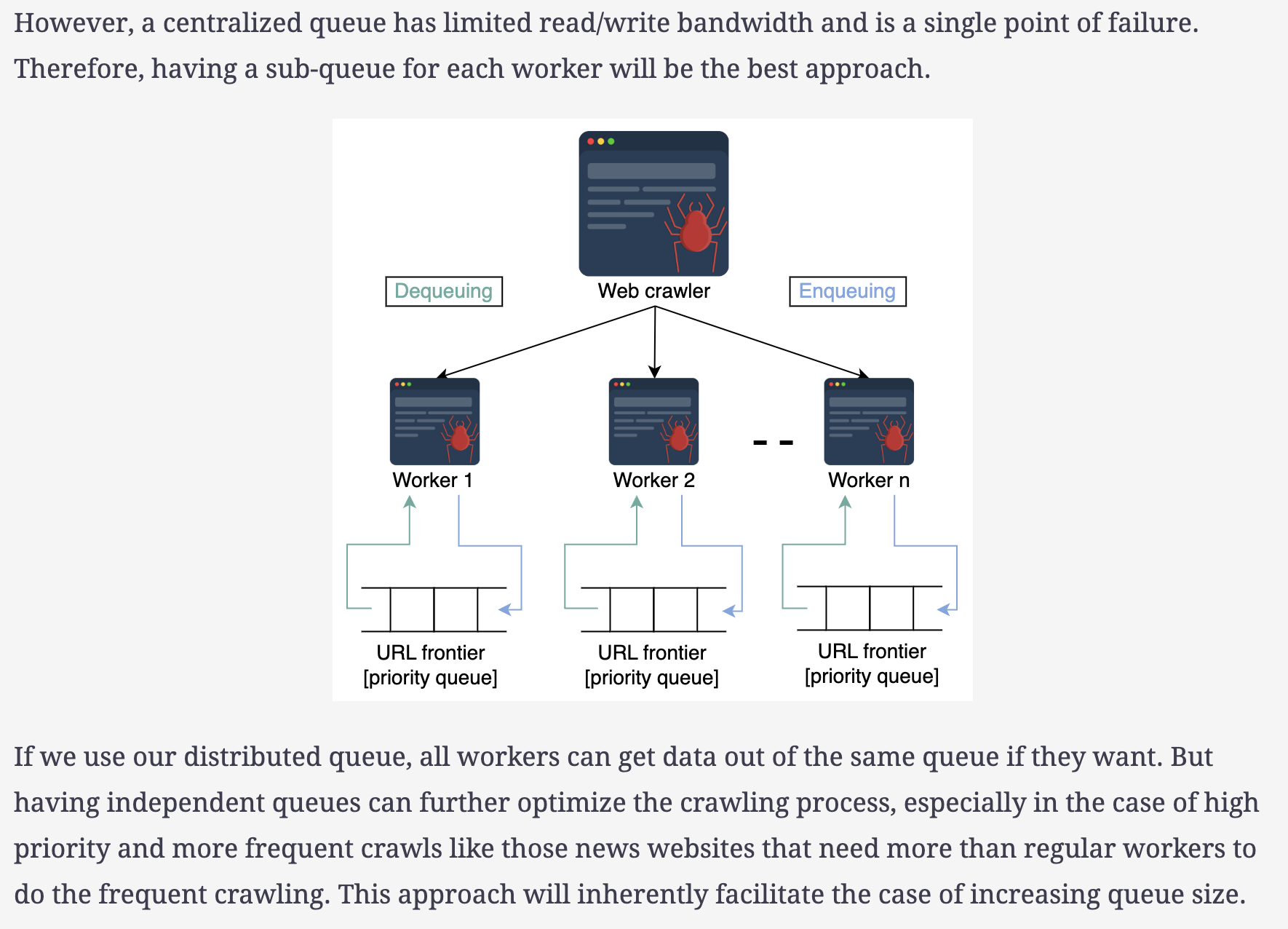
As was defined earlier, the URL frontier is a priority queue used in the scheduler and it holds the URLs that need to be crawled through. When we talk about its distribution, we mean taking the hash value of the hostname’s URLs and mapping them to specific workers. This way, each worker will have its own sub-queue.
This fulfills the following two requirements of our system:
- The workers don’t individually connect to more than one host web servers at a time.
- The workers don’t overburden the host web servers with concurrent requests because we use FIFO sub-queues.
--------------
- DNS resolver: The web crawler needs a DNS resolver to map hostnames to IP addresses for HTML content fetching. Since DNS lookup is a time-consuming process, a better approach is to create a customized DNS resolver and cache frequently-used IP addresses within their time-to-live because they’re bound to change after their time-to-live.
- HTML fetcher: The HTML fetcher initiates communication with the server that’s hosting the URL(s). It downloads the file content based on the underlying communication protocol. We focus mainly on the HTTP protocol for textual content, but the HTML fetcher is easily extendable to other communication protocols, as is mentioned in the section on the non-functional requirements of the web crawler.
Question
How does the crawler handle URLs with variable priorities?
The crawler has to be vigilant enough at each stage to differentiate between various priority levels of URLs.
Let’s see how the crawler design handles such cases stage by stage:
Since we implement our URL frontier as a priority queue of a scheduler, it automatically handles the placement based on parameter values. We have chosen the fault tolerance and periodicity parameters as priority indicators for our URLs.
The assignment of these parameters depends on the nature of the web pages’ content. If it is a news web page, crawling through it multiple times in a day is appropriate and required for our index to be up-to-date. Any ordinary web page with occasional updates happening might have a standard visit frequency of, let’s say, two weeks.
- Similarly, at the HTML-fetcher level where the crawler is communicating with the host server based on the
robots.txtguidelines, it can communicate the concerned parameter’s value for the fetched URLs back to the scheduler in the storing phase.
Instead of having indicators associated with the URLs, another solution can be to have separate queues for different priorities. We can then dequeue from these queues based on the priorities assigned to them. This approach just requires the URL placement in the respective queue and doesn’t need scripts to schedule based on the extra parameters associated.
It all depends on the scale of our crawling application.\ ---------------------
- Service host: This component acts as the brain of the crawler and is composed of worker instances. For simplicity, we will refer to this whole component or a single worker as a crawler. There are three main tasks that this service host/crawler performs:
- It handles the multi-worker architecture of the crawling operation. Based on the availability, each worker communicates with the URL frontier to dequeue the next available URL for crawling.
- Each worker is responsible for acquiring the DNS resolutions of the incoming URLs from the DNS resolver.
- Each worker acts as a gateway between the scheduler and the HTML fetcher by sending the necessary DNS resolution information to the HTML fetcher for communication initiation.
.png)
Extractor: Once the HTML fetcher gets the web page, the next step is to extract two things from the webpage: URLs and the content. The extractor sends the extracted URLs directly and the content with the document input stream (DIS) to the duplicate eliminator. DIS is a cache that’s used to store the extracted document, so that other components can access and process it. Over here, we can use Redis as our cache choice because of its advanced data structure functionality.
Once it’s verified that the duplicates are absent in the data stores, the extractor sends the URLs to the task scheduler that contains the URL frontier and stores the content in blob storage for indexing purposes.
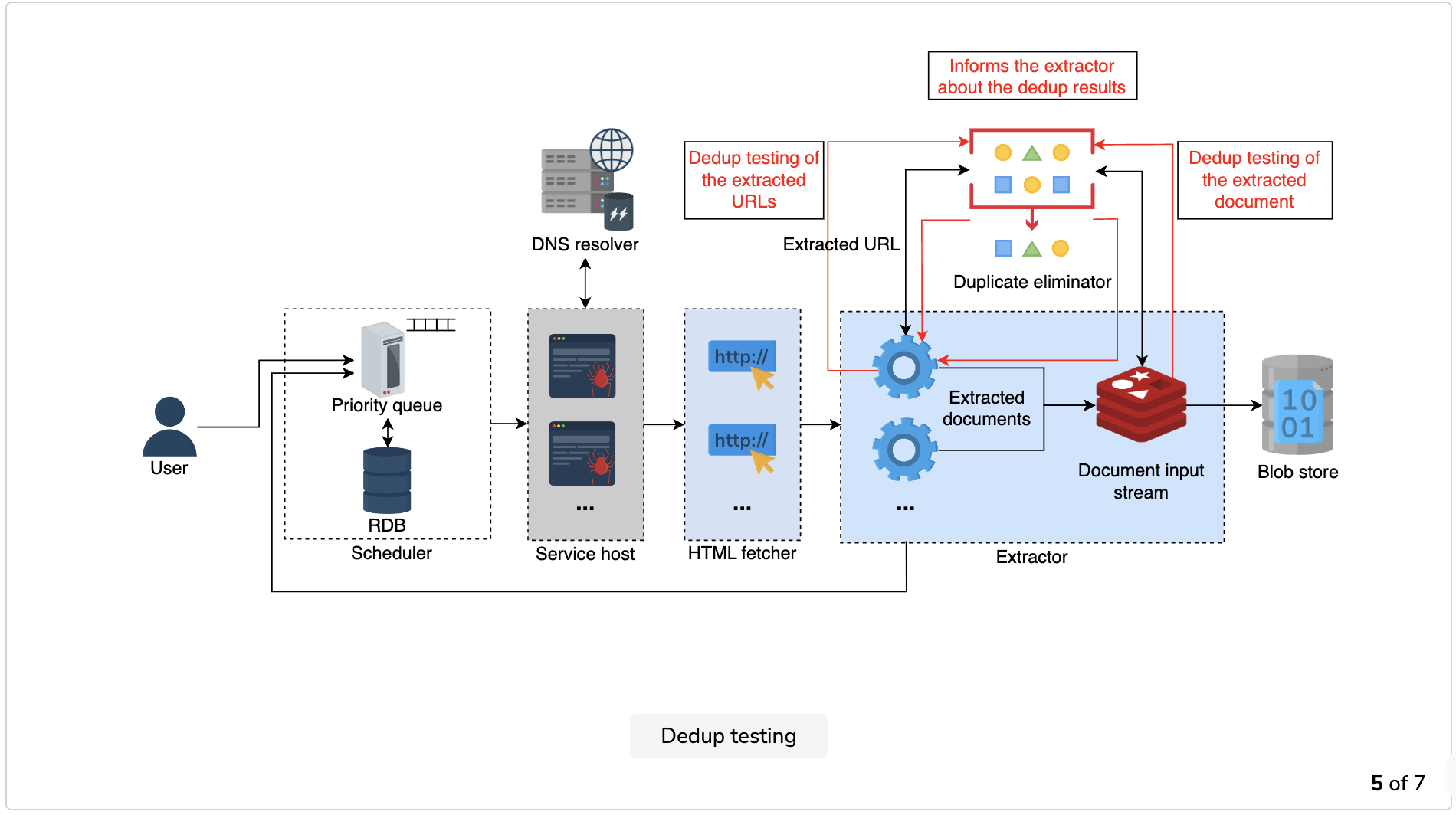
- Duplicate eliminator: Since the web is all interconnected, the probability of two different URLs referring to the same web page or different URLs referring to various web pages having the same content is evident. The crawler needs a component to perform a dedup test to eliminate the risk of exploiting resources by storing and processing the same content twice. The duplicate eliminator calculates the checksum value of each extracted URL and compares it against the URLs checksum data store. If found, it discards the extracted URL. Otherwise, it adds a new entry to the database with the calculated checksum value.
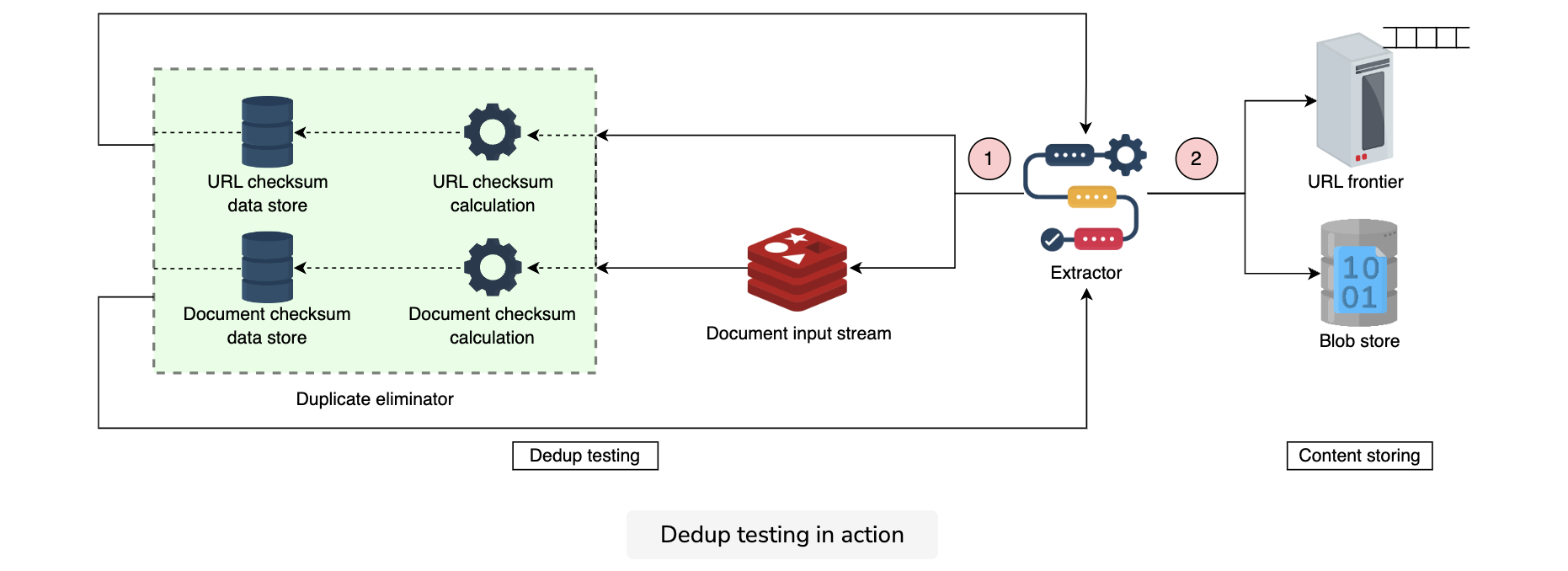
The duplicate eliminator repeats the same process with the extracted content and adds the new webpage’s checksum value in the document checksum data store for future matchings.
Our proposed design for the duplicate eliminator can be made robust against these two issues:
- By using URL redirection, the new URL can pass through the URL dedup test. But, the second stage of the document dedup wouldn’t allow content duplication in the blob storage.
By changing just one Byte in a document, the checksum of the modified document is going to come out different than the original one.
Blob store: Since a web crawler is the backbone of a search engine, storing and indexing the fetched content and relevant metadata is immensely important. The design needs to have a distributed storage, such as a blob store, because we need to store large volumes of unstructured data.
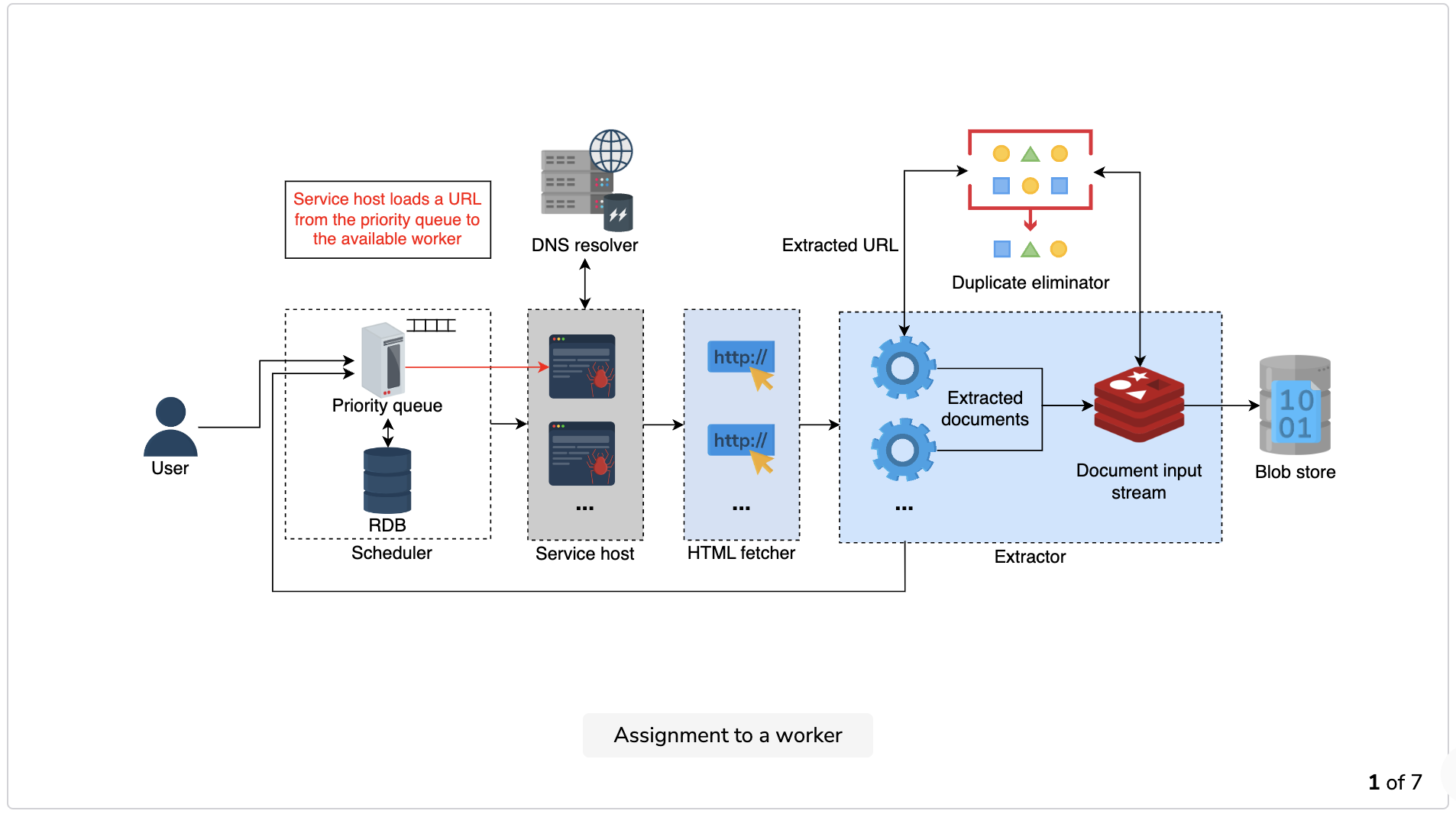
The following illustration shows the pictorial representation of the overall web crawler design:
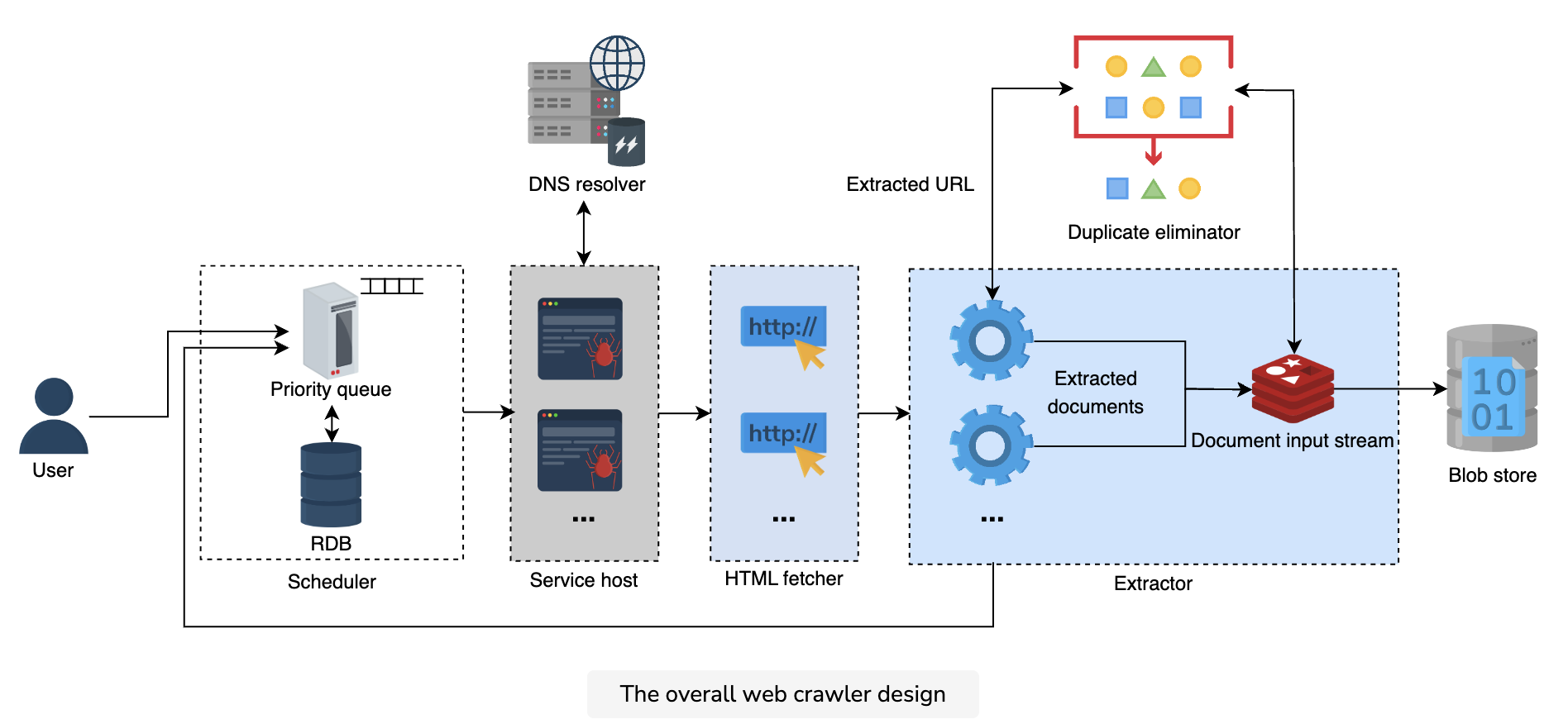
Workflow
- Assignment to a worker: The crawler (service host) initiates the process by loading a URL from the URL frontier’s priority queue and assigns it to the available worker.
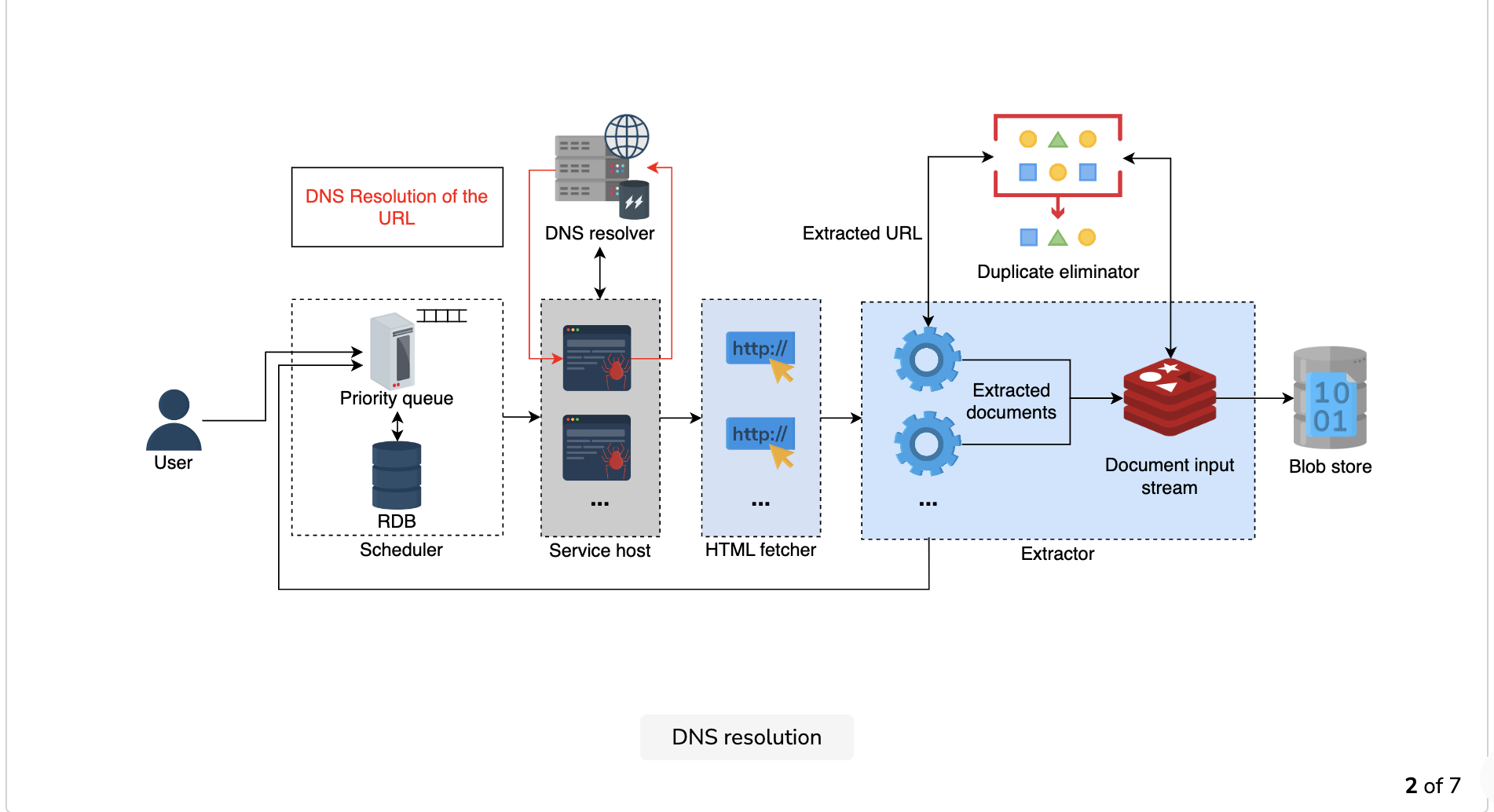
- DNS resolution: The worker sends the incoming URL for DNS resolution. Before resolving the URL, the DNS resolver checks the cache and returns the requested IP address if it’s found. Otherwise, it determines the IP address, sends it back to the worker instance of the crawler, and stores the result in the cache.
Point to ponder!\ The implementation of the URL frontier—dequeuing the URLs from a FIFO priority queue and enqueuing all the extracted URLs back into the queue rather than crawling them one after another—ensures that we are crawling the web in a breadth-first search (BFS) rather than a depth-first-search (DFS) manner.
---------------------------
Question
Can we use DFS instead of BFS?
We can use DFS when we want to utilize a website’s persistent connection to traverse all the web pages on that specific domain. This saves time as it helps us avoid reconnecting with the same website repeatedly in case the session expires.
--------------------------
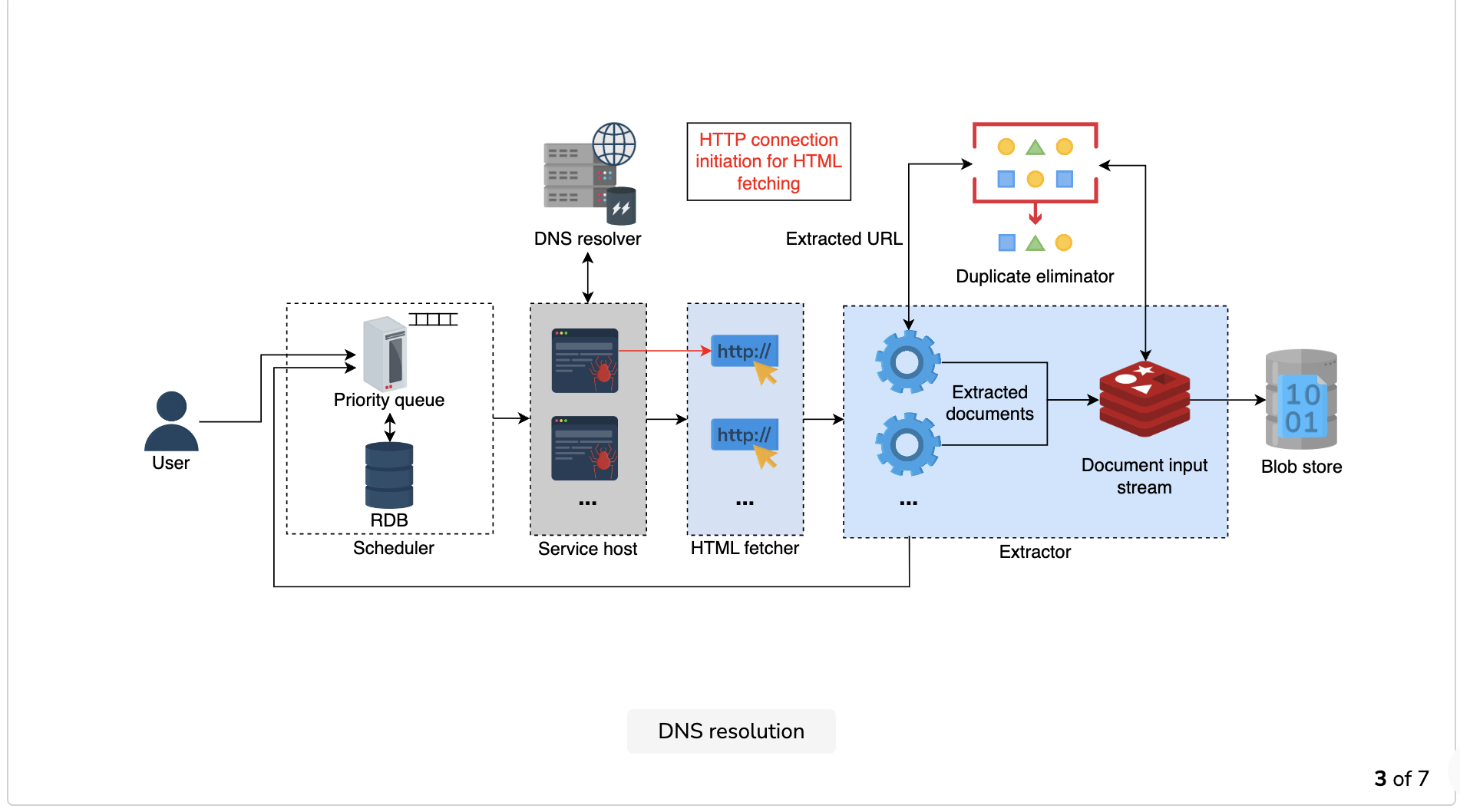
- Communication initiation by the HTML fetcher: The worker forwards the URL and the associated IP address to the HTML fetcher, which initiates the communication between the crawler and the host server.
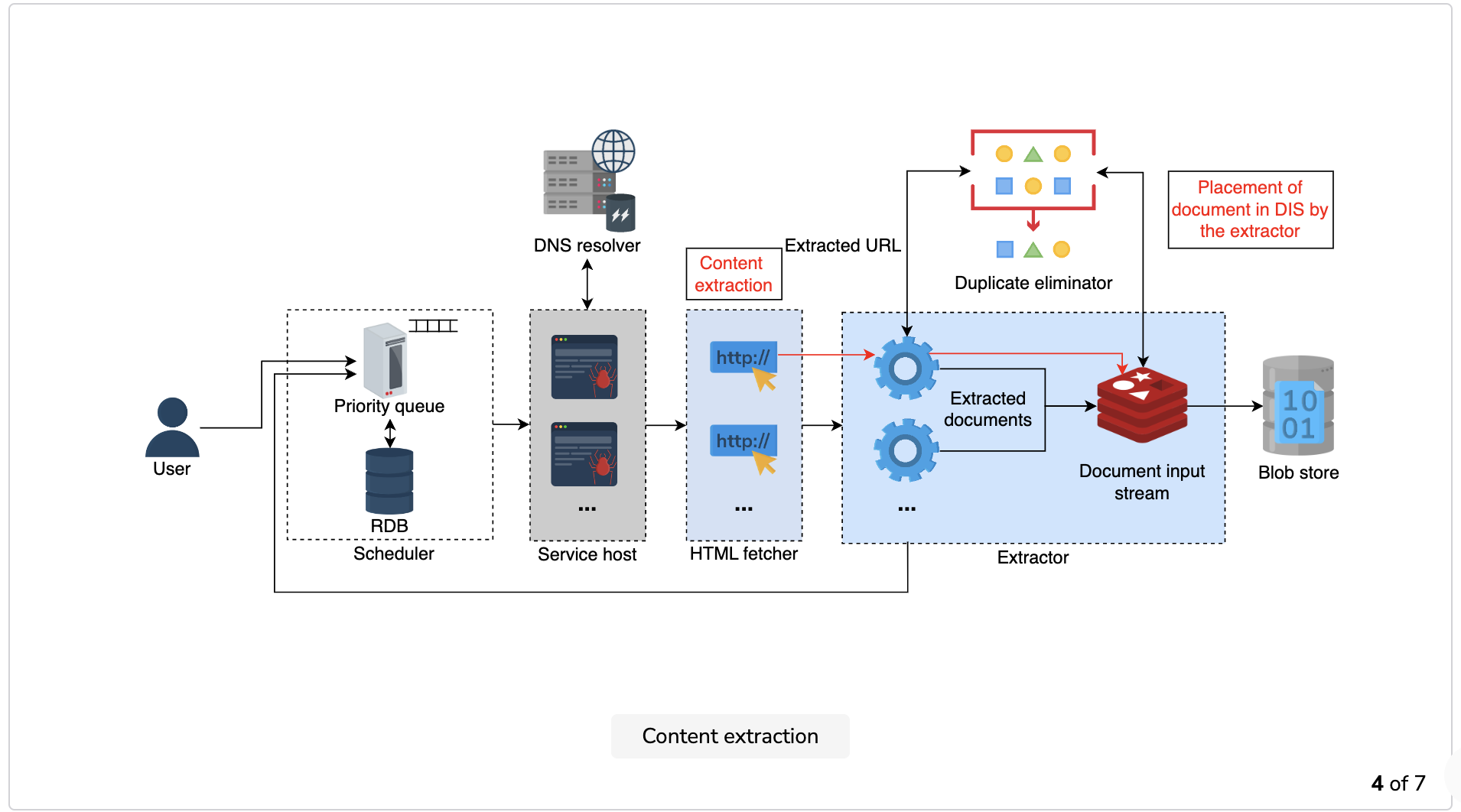
- Content extraction: Once the worker establishes the communication, it extracts the URLs and the HTML document from the web page and places the document in a cache for other components to process it.
Dedup testing: The worker sends the extracted URLs and the document for dedup testing to the duplicate eliminator. The duplicate eliminator calculates and compares the checksum of both the URL and the document with the checksum values that have already been stored.
The duplicate eliminator discards the incoming request in case of a match. If there’s no match, it places the newly-calculated checksum values in the respective data stores and gives the go-ahead to the extractor to store the content.
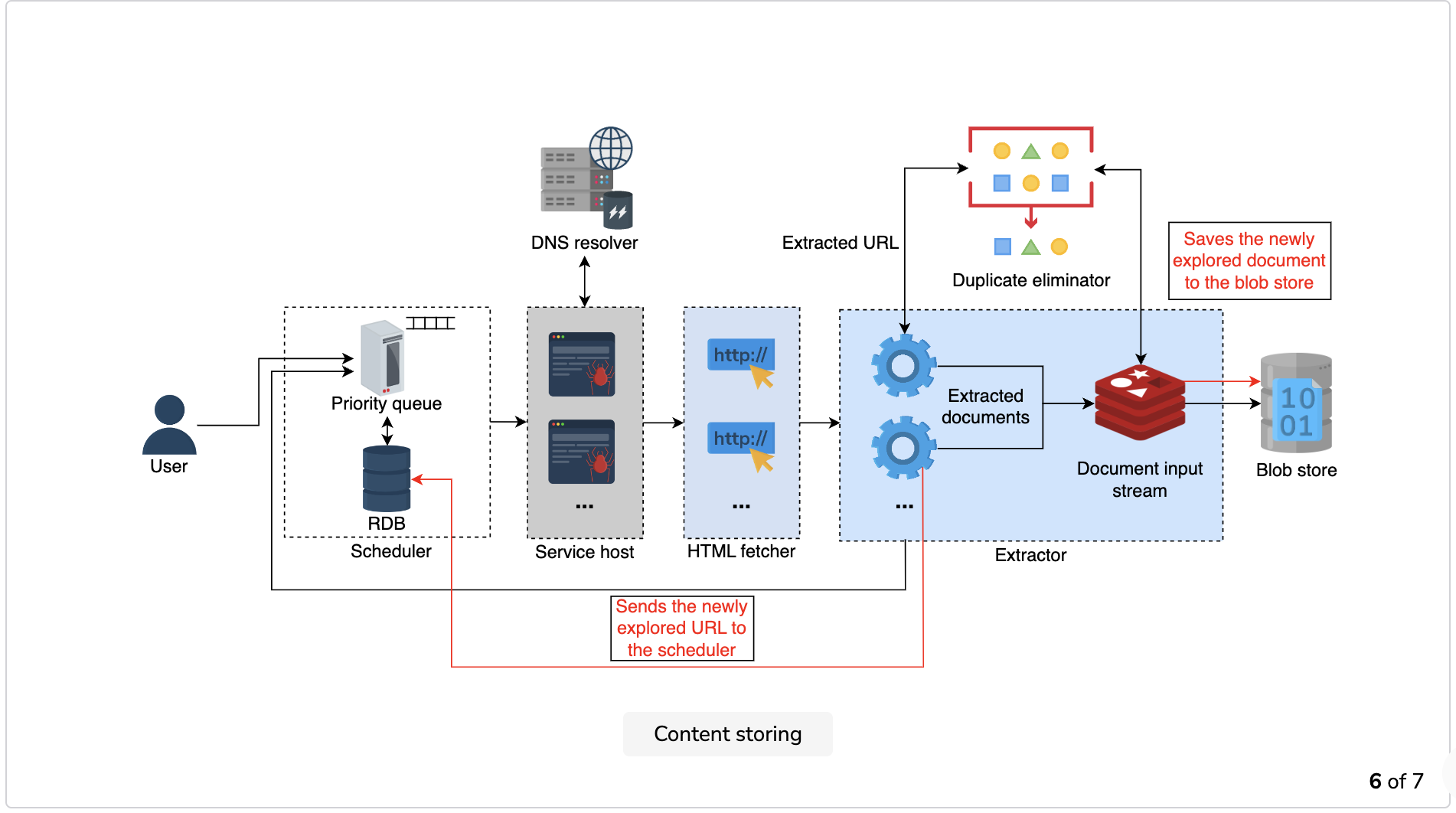
Content storing: The extractor sends the newly-discovered URLs to the scheduler, which stores them in the database and sets the values for the priority and recrawl frequency variables.
The extractor also writes the required portions of the newly discovered document—currently in the DIS—into the database.
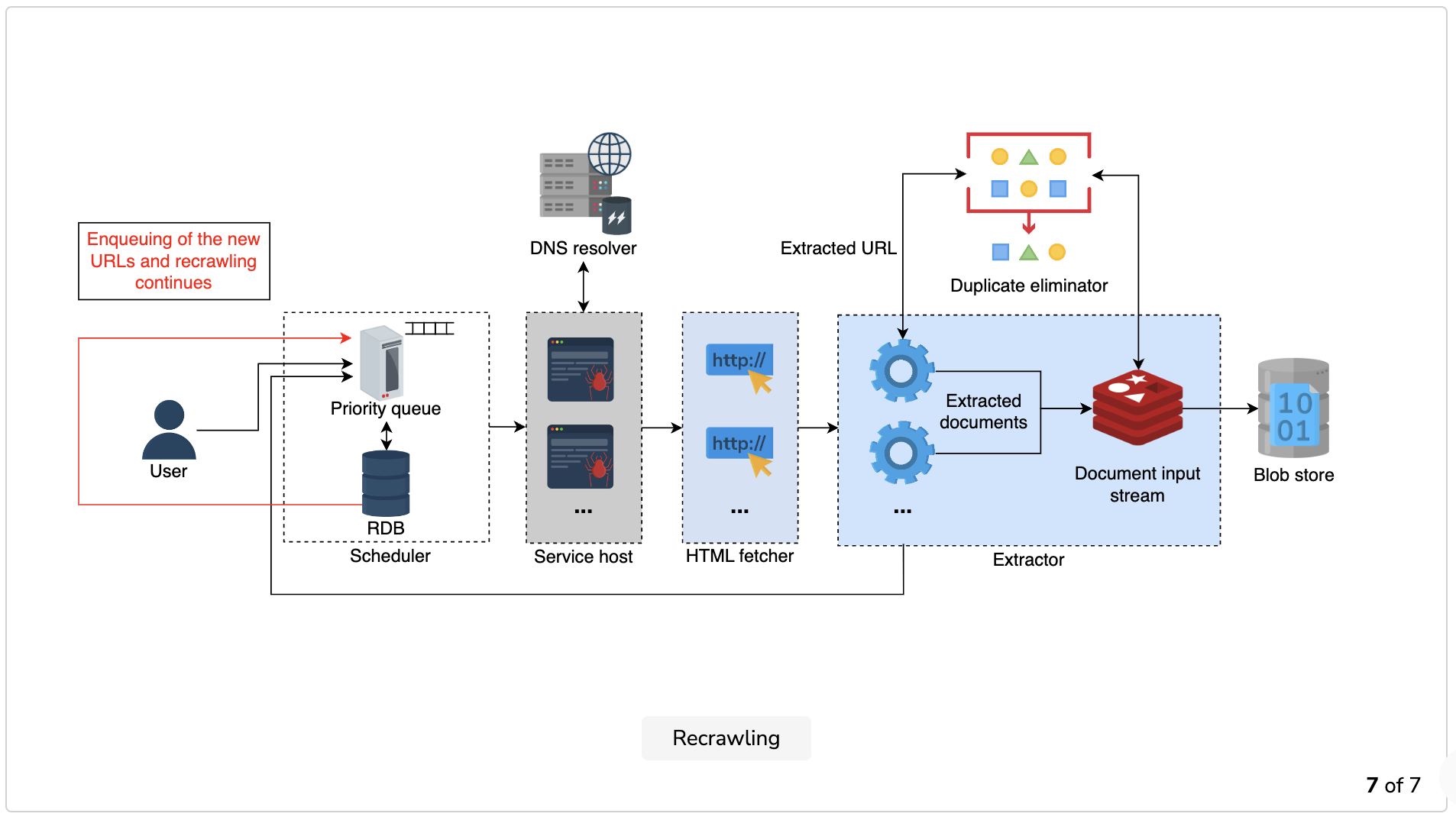
Recrawling: Once a cycle is complete, the crawler goes back to the first point and repeats the same process until the URL frontier queue is empty.
The URLs stored in the scheduler’s database have priority and periodicity assigned to them. Enqueuing new URLs into the URL frontier depends on these two factors.
Note: Because of multiple instances of each service and microservices architecture, our design can make use of client-side load balancing (see Client-side Load Balancer for Twitter).
The following slideshow gives a detailed overview of the web crawler workflow:
Question
How frequently does the crawler need to re-crawl?
Since crawling is not a one-time activity, the crawler needs to plan its default revisits with a suitable frequency. Let’s define this frequency of revisits as two weeks. The crawler revisits all the standard priority URLs every two weeks. Once the crawler visits a URL, it re-appends the same URL into the URL frontier with a default next visit time that’s equal to two weeks.
The default revisit-time is application-dependent rather than system-dependent, so we change this variable to cater to our needs. It’s a compelling case of assigning the priority comparator to URLs. Our system can predict the content change on a website using predictive analysis of the previous content changes. This way we can confidently assign the priority and revisit-time to each URL. For example, our analysis might show frequent changes on news websites and our crawler might suggest revisiting them on a high priority after every five minutes.\ ----------------
In the next lesson, we’ll explore some shortcomings in our design and their potential workarounds.